이전 글
[Java] 동시성 처리 - intro
앞선 글에서 자바의 동시성을 이야기하며, 자바에서의 Lock 사용법을 위주로 설명하였습니다. 자바 내장 모듈이 기본적으로 지원하는 API를 활용해서 동시성을 처리한다면, 까다로운 구현 없이 처리할 수 있을 것입니다. 하지만 각 API가 어떻게 성능을 개선해왔는지를 이해하기 위해서는 그 작동방식에 대해서 이해해야 할 필요가 있습니다. 이를 위해 이번 글에서는 일반적인 lock algorithm에 대해서 살펴보고자 합니다. 그 전에 blocking과 non-blocking에 대해서 먼저 살펴보고자 합니다. 각 알고리즘들은 상황에 따라 blocking과 non-blocking 개념을 적절히 활용하여 구현되고 있기 때문입니다.
Blocking - Non-Blocking
Blocking
앞선 글에서 살펴보았던 synchronized method, synchronized statements 등은 모두 blocking algorithm에 해당합니다. 아래 그림에서 보면 Thread B가 공유자원에 접근하게 되어 lock을 걸고, Thread B가 공유자원에 동시접근 한다면, blocking 되어 기다리다가 Thread A가 unlock 한 시점에 lock을 획득할 수 있게 됩니다.
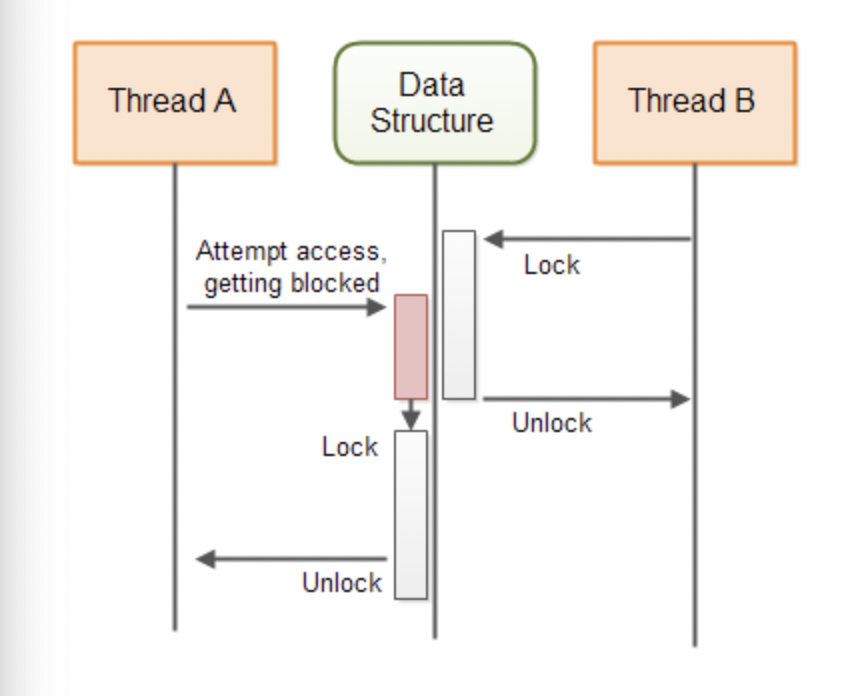
blocking 기반의 lock에서는 데드락이나 성능 저하 등의 문제점이 발생할 수 있습니다.
데드락
데드락의 발생 조건은 보통 4가지로 분류됩니다. 상호 배제(Mutual Exclusion), 점유 대기(Hold and Wait), 비선점(No Preemption), 순환 대기(Circular wait)가 그것입니다. 만약 blocking lock에서 별다른 처리를 하지 않는다면, 데드락 발생 가능성이 있습니다. 예를 들어 Thread C가 동시에 작업을 하면서 위에서 설명한 공유자원 이외의 다른 공유자원2의 lock을 획득한다고 가정해봅시다. 이 때, Thread B가 공유자원1의 lock을 획득하고 unlock 전에 공유자원 2의 접근이 필요할 수도 있습니다. 동시에 Thread C가 공유자원1의 잠금을 획득해야 할 수 있습니다. 이 경우 Thread B는 공유자원1의 lock을 획득한 상태에서 공유자원2의 unlock을 기다리게 되고, Thread C는 공유자원 2의 lock을 획득한 상태에서 공유자원1의 unlock을 기다리게 되어 데드락이 발생할 수 있습니다.
성능 저하
데드락 없이 공유자원에 여러 스레드가 접근할 수 있다고 하더라도, blocking 된 시점에서 대기해야 하는 시간으로 인해 성능 저하가 발생할 수도 있습니다. Thread A가 lock을 획득한 시점에서, Thread B가 lock 획득을 위해 기다려야 하는 시간이 유의미하게 크다면, 원하는 성능을 기대할 수 없을 것입니다.
Non-Blocking
아래 그림에서 보듯이 Thread B가 공유자원에 먼저 접근하게 되면, Thread A는 lock을 획득하기 위해 기다리지 않고 즉시 반환됩니다.반환 후 종료될 수도, 다시 lock을 획득하기 위한 작업을 재시도 할 수도 있을 것입니다. blocking과의 가장 큰 차이점은, 작업 요청 후 수행이 불가능할 때 단순히 기다리지 않고 수행이 불가능함을 반환할 수 있다는 점입니다.

Lock Striping
Lock Striping은 동시성 기술을 구현할 때 lock을 획득하기 위한 경쟁을 완화하여 lock 사용 시의 성능을 높여줍니다. lock이 필요한 전체 작업이 있다면, 그 작업들을 작은 단위들로 다시 나누어 필요한 부분에서만 lock 경쟁 상황이 벌어지게 만드는 것입니다.
Java의 ConcurrentHashMap을 보면 Map이 갖고 있는 Entry들은 Node<K, V> 객체의 배열인 table 단위로 표현됩니다. 각 Node들은 hash 값과 key, value, next Node 값을 가지고 있습니다.
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>
implements ConcurrentMap<K,V>, Serializable {
transient volatile Node<K,V>[] table;
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
//...
}
}ConcurrentHashMap의 구현체에서 get() 메서드 등을 통해 값을 read 할 때는 별다른 잠금이 일어나지 않습니다. 하지만 put() 메서드 등 값을 write 해야할 때는 잠글 필요가 있는 Node 객체의 잠금을 획득하여 처리하고 있습니다. 중간에 CAS(Compare And Set) 개념이 나오는데 뒤이어 설명하도록 하겠습니다. 지금은 특정 Node<K,V> f 에만 synchronized statements를 이용해 동기화 하고 있다는 점을 확인해보겠습니다.
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
//...
for (Node<K,V>[] tab = table;;) {
//...
// no lock when adding to empty bin
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break;
}
//...
// check first node without acquiring lock
synchronized (f) {
// implementations
}
}
return null;
}
Lock-Free
lock free 알고리즘은 엄밀히 따지면 lock을 사용하지 않고 동시성 이슈를 해결하는 기술입니다. 특정 공유자원의 lock을 획득함으로써 데이터의 정합성을 보장하는 것이 아니라, 일련의 operation 작업의 원자성(atomicity)을 보장하도록 하여 간섭 없이 공유 자원을 변경할 수 있도록 합니다. 특히, blocking을 통해 공유 자원 접근 제한을 두는 것이 아니라, non-blocking 기반으로 해당 자원이 변경될 수 있는 상태인지에 대한 결과를 반환 받아 작업을 처리하는 데 중점이 있습니다.
이 중에서 CAS(compare-and-set or compare-and-swap) 연산에 대해서 알아보도록 하겠습니다.
특정 값을 변경하기 위해서는 해당 값을 먼저 읽고(read), 변경(modify)시킨 뒤, 쓰는(write) 작업이 필요합니다. 해당 작업이 여러 스레드에서 동시에 일어나게 된다면, 각 스레드의 read-modify-write 작업 시간에 따라 원치 않는 결과가 반환될 수도 있습니다. 하지만 CAS 연산에서는 read-modify-write 연산의 원자성을 보장하여 별도의 lock 없이 동시성 이슈를 해결하도록 하고 있습니다.
기본적으로 CAS 연산은 3개의 인자를 넘겨줍니다. 작업 대상의 메모리 위치(V), 예상하는 기존 값(A), 새로 설정할 값(B)입니다. V 위치에 있는 값이 A와 같은 경우에 B로 변경하는 단일 연산입니다. 만약 기존 값이 A와 다르다면 값을 변경시키지 않습니다.
이전 글에서 다루었던 java.util.concurrent.atomic 패키지에 있는 AtomicInteger, AtomicReference 등의 클래스에서 CAS 연산을 지원하고 있습니다.
public class AtomicInteger extends Number implements java.io.Serializable {
private static final Unsafe U = Unsafe.getUnsafe();
private static final long VALUE = U.objectFieldOffset(AtomicInteger.class, "value");
//...
}Unsafe 객체의 objectFieldOffset 메서드는 파라미터로 전달받은 객체 값(value)의 메모리 offset 을 반환합니다. Unsafe는 low-level에서 수행되는 연산을 지원하기 위한 객체 정도로 이해하면 됩니다. AtomicInteger 클래스에서는 getAndAdd(), getAndIncrement(), getAndAccumulate() 등의 다양한 기능을 제공하지만, 기본적인 개념을 알아보기 위해 compareAndSet() 메서드를 통해 살펴보겠습니다.
public final boolean compareAndSet(int expectedValue, int newValue) {
return U.compareAndSetInt(this, VALUE, expectedValue, newValue);
}파라미터로 expectedValue와 newValue를 전달합니다. Unsafe 객체의 compareAndSetInt() 메서드 시그니처를 보면, 연산이 필요한 객체와 VALUE(위에서 설명한 value의 메모리 offset), 기댓값과 새로운 값을 전달합니다. 앞서 다루었던 CAS의 기본 연산에서 전달하는 파라미터와 유사합니다.
@Test
void CAS_연산() {
AtomicInteger atomic = new AtomicInteger();
/* 초기값 확인 */
int currVal = atomic.get();
System.out.println("currVal = " + currVal);
/* CAS 연산 성공 */
boolean flag = atomic.compareAndSet(0, 100);
currVal = atomic.get();
System.out.println("flag = " + flag);
System.out.println("currVal = " + currVal);
/* CAS 연산 실패 */
flag = atomic.compareAndSet(0, 200);
currVal = atomic.get();
System.out.println("flag = " + flag);
System.out.println("currVal = " + currVal);
}
currVal = 0
flag = true
currVal = 100
flag = false
currVal = 100
AtomicInteger 인스턴스를 생성하고 초기값을 확인합니다. 0입니다. 이후 CAS 연산을 실행합니다. 현재값인 0과 변경할 값인 100을 파라미터로 전달합니다. 해당 CAS연산이 성공하여 true를 반환하고 결과값도 100입니다. 다음 CAS 연산에서는 현재값이 100이므로 변경할 값인 200을 전달해도 연산에 실패하여 false를 반환하고 현재값도 100이 유지됩니다.
[참고자료]
https://jenkov.com/tutorials/java-concurrency/non-blocking-algorithms.html
'java' 카테고리의 다른 글
| [Java] 테스팅 툴 - JMeter (1) | 2023.02.21 |
|---|---|
| [Java] 모니터링 툴 - VisualVM (0) | 2023.02.19 |
| [Java] Garbage Collection(GC) 변천사 (0) | 2023.02.14 |
| [Java] Java Virtual Machine(JVM) (0) | 2023.02.12 |
| [Java] 동시성 처리 - intro (0) | 2023.02.12 |



